Almost 90% of data science projects never make it past the development phase into production. There are a variety of root causes for this outcome – from low model performance to difficulties with integrating solutions into existing workflows. In addition, the 10% of solutions that do make it into production still need to be monitored and maintained over time to ensure quality as data continues to change. We overcome these challenges and drive successful customer outcomes by following our predefined process for configuration and deployment of our document processing solutions.
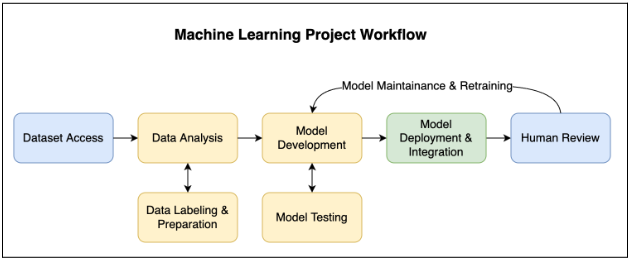
Figure 1. A typical machine learning solution development at Infinia ML
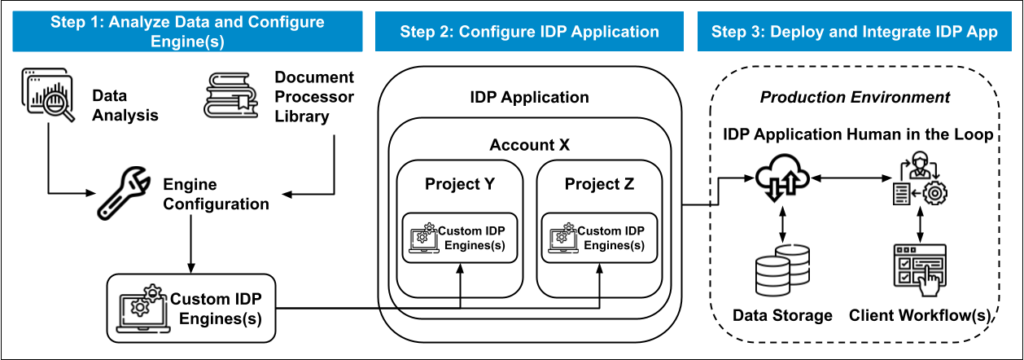
High model accuracy starts with quality labeled training data. Our approach is to invest time earlier in a project to prepare a fulsome set of labeled data which yields improvements in initial model performance. Once we have labeled data, we start model development and testing. We are able to customize and build on top of Infinia ML’s Document Processor Library to develop custom solutions to solve a wide variety of use cases. This model development process is iterative, and while we use tools to accelerate our work, our data scientists take a hands-on approach to configure solutions to exact customer requirements. When our Data Science team is happy with our models’ performance, we can move on to the most critical step of the process: deploying and integrating the ML solution into existing production workflows.
Historically, we have seen difficulties during the deployment and integration process. To help facilitate this, we have developed our Intelligent Document Processing (IDP) Platform with standardized deployment and integration steps. The custom model we developed in earlier steps is contained within an IDP Engine, which is deployed to the IDP Platform. After the custom Engine is deployed into production, data can be sent for processing either through our platform’s user interface (UI), programmatically through custom APIs, or automatically processed from a connected storage location.
Data embedded within documents is never static, so the IDP Platform enables a continuous Human In The Loop (HITL) document review process to improve model accuracy over time. Depending on the existing production workflow, our engines will identify documents which require additional human feedback. In the IDP UI, users will be guided to which documents and data require review. IDP saves off this new ground truth data and periodically uses it to retrain and retest the model. When confirmed improvements are seen, the updated model is deployed to the IDP platform.
Figure 2. The standard configuration and deployment process for the IDP Platform