
Authors:

Ya Xue, Ph.D.
VP, Data Science

John Sigman, Ph.D.
Principal Data Scientist

Chase McGrath
Director, Product & Sales
The Power of Generative AI
Constraints of GPT Technology
GPT / LLM solutions are built for text generation and therefore, they come with some limitations in the IDP (Intelligent Document Processing) setting. GPT model responses to input prompts are generated non-deterministically – put another way, the response could be different each and every time. Responses are also generated without a corresponding confidence score. Without a confidence score, it’s unknown how trustworthy the response truly is. If the model’s response is wrong, it’s ultimately up to a human to judge the accuracy of the response. GPT model interfaces to interact with the technology were also designed as conversational chatbots and are thus not ideal for implementation of high-throughput process optimization solutions. Consequently, longer documents must be broken into smaller sections of plain text for processing by GPT models. This workaround slows the overall processing speed and discards the contextual value of each document’s format and layout. In addition, using plain text for the GPT model input omits structural information to correctly identify more complex document components such as nested tables and sub-section headers. Once results are generated by the GPT model, the output is displayed in plain text either through a web interface or an API response. Analyzing data annotations out of the document context makes it difficult to visualize and validate whether all or part of the model response is correct.
A Hybrid Solution for Document Processing
Combining the data extraction strength of LLMs with the workflow and data pipeline capabilities of an IDP platform provides a more robust and accurate solution for document analysis challenges. For almost any application, an IDP platform can take long-form documents in image or rich text format, convert them to chunks of text with contextual information embedded in, programmatically generate multiple prompts, and then leverage a GPT model to identify data of interest in the text based on the prompt. The output from GPT can then be used as an input for other pieces of the document processing pipeline within the IDP platform. As an example, GPT can first capture unique names within a document. The labeled names are then automatically compared against the national provider registry to validate specific mentions of providers within the document. Once the document is processed, human reviewers view the labeled providers within the document as part of the IDP platform’s human-in-the-loop interface and make any corrections to the data as needed. While most IDP platforms can be part of a hybrid solution, choosing the right one is critical to maximizing the impact of GPT models for intelligent automation of document-based processes.
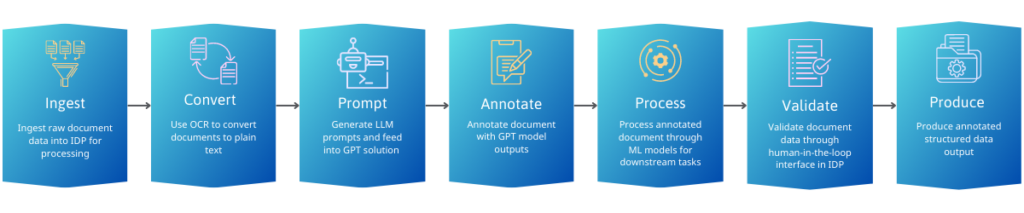
(Hybrid document processing pipeline with data extraction using GPT)
Infinia ML’s Hybrid IDP Approach
In contrast to GPT solutions alone, Infinia ML’s IDP platform provides an end-to-end workflow for processing documents and identifying data, reviewing and validating processed documents, and collecting data for model retraining and improvement over time. In addition, this platform is capable of high-performance processing on long, complex, and unstructured data. With LLM capabilities as part of the Infinia ML team’s capability set, we are transforming how quickly and effectively we implement IDP solutions for our customers. Whereas previously, the availability and quality of human labeled data adversely affected model accuracy and training time, GPT solutions enable us to now train and deploy performant models in a fraction of the time with a much smaller set of labeled data. Not only has this resulted in price reductions for our IDP solution, but our team can deploy more complex solutions in much shorter timeframes, significantly improving the time to value for our customers.
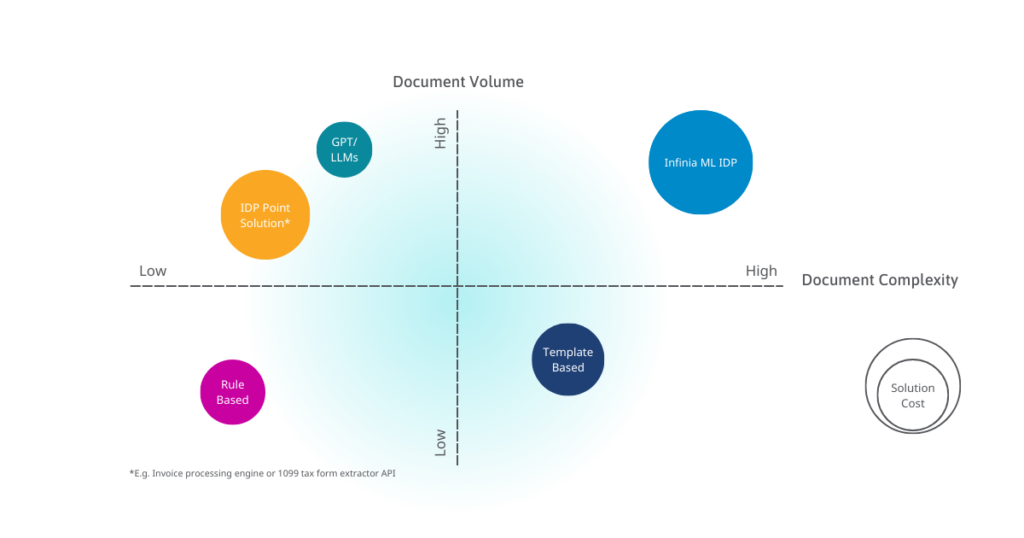
(Infinia ML’s IDP Platform vs other document processing solutions)
In Conclusion
GPT / LLM models are powerful tools for entity extraction with little to no training data required. However, the randomness of responses, lack of confidence scoring, and inability to analyze textual data in context limit the potential applications of GPT as a complete solution for intelligent automation. In combination with an IDP platform that has a human-in-the-loop interface, GPT models can accelerate timelines to train and refine document analysis models and provide a true end-to-end workflow solution to support business processes. The Infinia ML team has pioneered the use of LLM technology to rapidly develop and deploy powerful solutions for document processing. Our IDP deployment is now faster and more cost-effective than ever before in our history.